Add DynamoDB Streams processor
Something in our metrics for get-order is not working as we’d hope. The low hit rate (around 85%) is a hint for us to understand what is happening. Within our load generation workflow, we’re first writing a new order, and then we read it back a number of times. Of course, the first read is a cache miss - the subsequent cache reads are hits. Whenever we have a cache miss, we spend time first checking for an item in the cache and finding it missing. Then we go to the database, and finally we write the database result back into the cache (ready for next time). To get the best possible results, we’d really like to avoid that first read of a new item being a miss.
It’s said that one of the hardest things in software engineering is cache invalidation.
What is cache invalidation?
When an item is updated in the database, we want to update it in the cache as well. This is to avoid having applications see overly stale data. Expiration (automatically deleting a cache item when the time to live (TTL) is passed) is one simple and very effective way to control for this. Momento has us covered for expiration. With a configurable TTL, the Momento SDK allows users to configure the length of time data can be cached before being automatically deleted. Ranging from 1 second up to 24 hours, once a TTL expires, your data will be removed from the cache.
But what about data that has been updated in the database before the TTL expires? Or data newly inserted into the database (such as the new orders submitted which are causing our get-orders API to give only a 75% hit rate)? What can we do there?
Write-aside caching
One way to improve this is to implement a write-aside pattern. Whenever we make a write to the database, we update the cache accordingly. Depending on the code, this can add considerable complexity. Thankfully, in this case we can leverage DynamoDB Streams to simplify the process.
What is DynamoDB Streams?
When you make create, update, or delete a record in a DynamoDB table, you can opt to have the change event added to a resource called a stream. This is essentially change data capture - you may be familiar with this from other databases. We’ll implement a triggered Lambda function to read from the change events and write the changes out to the cache, keeping it up-to-date with the latest data changes.
With this in mind, let’s take a look at what our new architecture becomes 👇
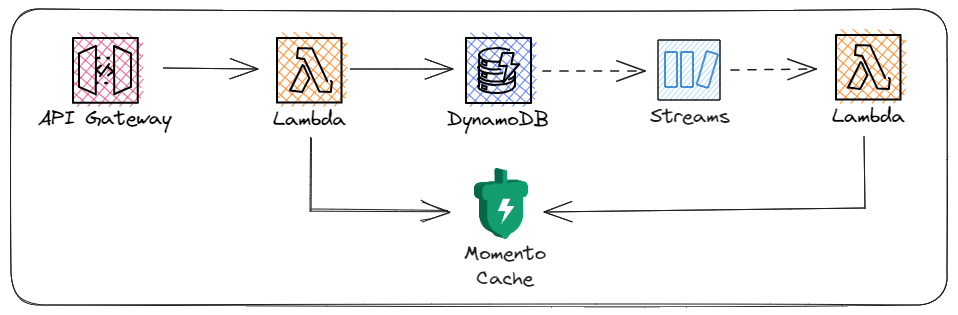
Components
To utilize a DynamoDB stream, we’ll perform the following actions in the coming pages:
- Update the template.yaml file to create a DynamoDB Stream resource
- Update the template.yaml file to enable a Lambda function which will be triggered from the stream
- Update the template.yaml file to connect the stream to the Lambda function
- Redeploy
Not too bad, right? Let’s go make it work!